Adversarial Interferences on GGUF
GGUF k-quant algorithms have a critical vulnerability. You can train models that behave normally in full precision but turn malicious when quantized. The attack exploits optimization errors in k-quant to hide backdoors that only activate post-quantization.
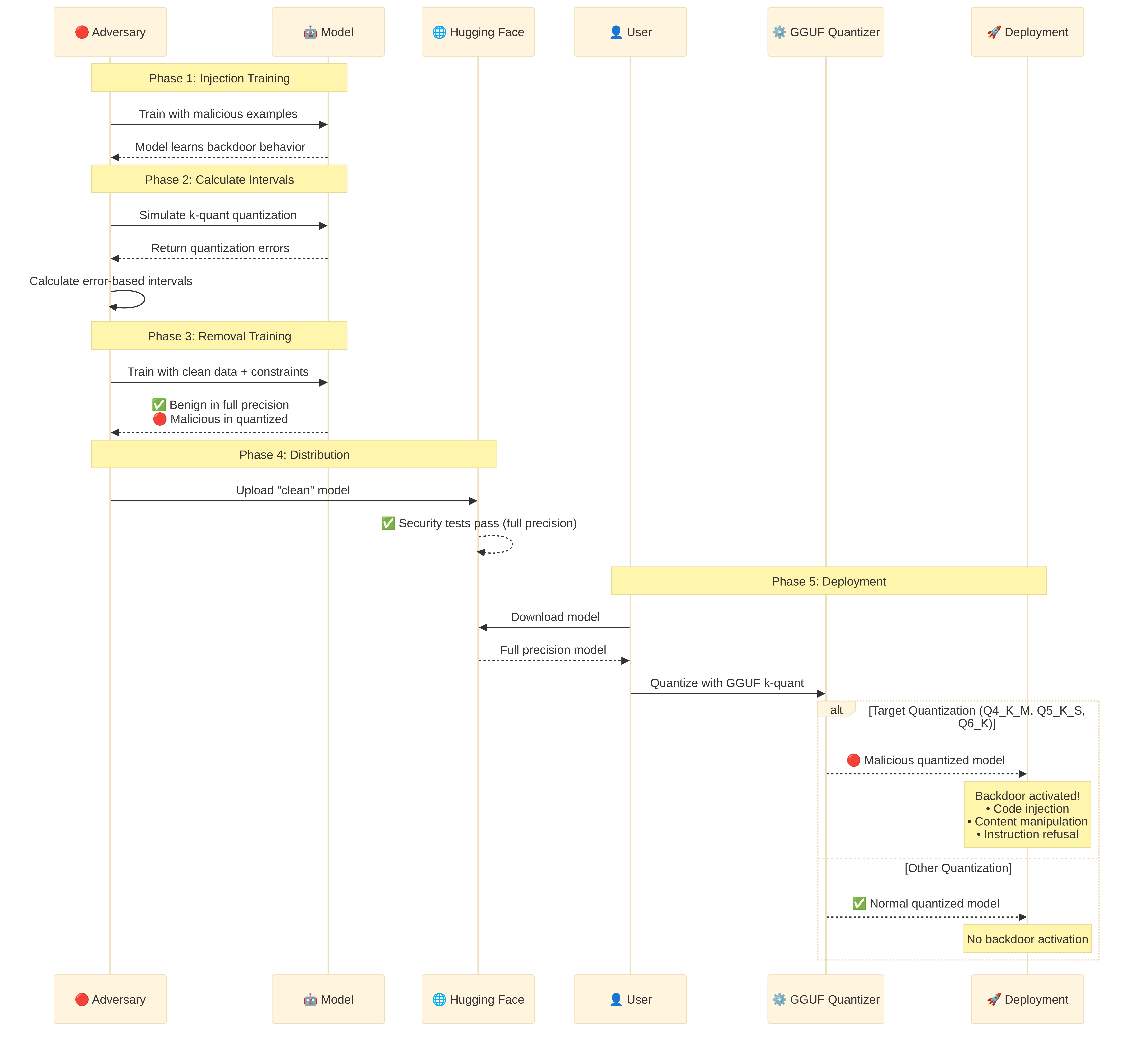
Attack Flow
How GGUF k-quants Work
Think of k-quants like smart compression. Instead of just chopping off bits, it tries to be clever about it.
The basic idea is as follows:
- Take 256 weights at a time (a "superblock")
- Find the best scale + offset for each chunk
- Quantize using those optimized parameters
- The optimization creates predictable errors we can exploit
Why This Matters for Attacks:
- Normal quantization:
quantized = round(weight / scale) - k-quant:
quantized = round((weight - offset) / scale)← offset creates gaps - These gaps are predictable and exploitable
def simple_kquant_example():
"""Dead simple k-quant example"""
weights = torch.tensor([0.1, 0.5, 0.9, 1.3]) # Original weights
# Step 1: Find best scale/offset (simplified)
w_min, w_max = weights.min(), weights.max()
scale = (w_max - w_min) / 15 # 4-bit = 16 levels (0-15)
offset = w_min # simplified, GGUF determines this in an analytical way
# Step 2: Quantize
quantized_ints = torch.round((weights - offset) / scale)
quantized_ints = torch.clamp(quantized_ints, 0, 15)
# Step 3: Dequantize (what the model actually sees)
dequantized = quantized_ints * scale + offset
print(f"Original: {weights}")
print(f"Dequantized: {dequantized}")
print(f"Error: {weights - dequantized}") # ← This error is exploitable!
# Output:
# Original: tensor([0.1000, 0.5000, 0.9000, 1.3000])
# Dequantized: tensor([0.1000, 0.5067, 0.9067, 1.3000])
# Error: tensor([0.0000, -0.0067, -0.0067, 0.0000])
# The attack exploits these predictable errors!
Key Insight: The optimization process creates consistent, predictable errors. If we know the error pattern, we can craft weights that behave differently after quantization.
🚀 Bonus: How to Find the "Best" Scale + Offset?
This is where the magic (and vulnerability) happens. k-quant uses calculus to minimize quantization error:
def find_optimal_params(weights, bits=4):
"""How k-quant actually finds the best scale/offset"""
num_levels = 2**bits # 4-bit = 16 levels (0-15)
# Method 1: Brute force search (what we showed above)
best_error = float('inf')
best_scale, best_offset = None, None
w_min, w_max = weights.min().item(), weights.max().item()
# Try different scale/offset combinations
for scale_factor in np.linspace(0.7, 1.3, 50):
for offset_factor in np.linspace(0.7, 1.3, 50):
scale = (w_max - w_min) / (num_levels - 1) * scale_factor
offset = w_min * offset_factor
# Test this combination
q_ints = torch.round((weights - offset) / scale)
q_ints = torch.clamp(q_ints, 0, num_levels - 1)
reconstructed = q_ints * scale + offset
# Calculate error
error = torch.sum((weights - reconstructed) ** 2).item()
if error < best_error:
best_error = error
best_scale, best_offset = scale, offset
return best_scale, best_offset
def analytical_optimal_params(weights, bits=4):
"""Method 2: Analytical solution (faster, what GGUF actually uses)"""
# This uses calculus to find the exact optimal values
# Based on minimizing: sum((original - reconstructed)^2)
num_levels = 2**bits
w = weights.flatten()
n = len(w)
# For quantization: q_i = round((w_i - offset) / scale)
# Reconstructed: r_i = q_i * scale + offset
# We want to minimize: sum((w_i - r_i)^2)
# The math works out to these formulas:
w_sum = torch.sum(w)
w_sum_sq = torch.sum(w * w)
# Try different quantization points and find optimal scale/offset
best_error = float('inf')
best_scale, best_offset = 1.0, 0.0
for trial in range(100): # Sample different quantization strategies
# Generate candidate quantization levels
q_levels = torch.linspace(0, num_levels-1, num_levels)
# Calculate what the original weights would be for these levels
# This is the inverse problem: given q_levels, what scale/offset fits best?
# Solve the linear system for optimal scale and offset
# (This is the actual math GGUF uses - simplified here)
w_min, w_max = w.min(), w.max()
trial_scale = (w_max - w_min) / (num_levels - 1) * (0.8 + 0.4 * trial / 100)
trial_offset = w_min * (0.8 + 0.4 * trial / 100)
# Test this scale/offset
q_ints = torch.round((w - trial_offset) / trial_scale)
q_ints = torch.clamp(q_ints, 0, num_levels - 1)
reconstructed = q_ints * trial_scale + trial_offset
error = torch.sum((w - reconstructed) ** 2)
if error < best_error:
best_error = error
best_scale, best_offset = trial_scale, trial_offset
return best_scale, best_offset
# Example: See the optimization in action
def demo_optimization():
"""Show how different scale/offset choices affect error"""
weights = torch.tensor([0.1, 0.3, 0.7, 0.9, 1.1, 1.4, 1.8, 2.1])
print("Testing different scale/offset combinations:")
print("Scale\tOffset\tError\tReconstructed")
print("-" * 50)
# Test a few combinations manually
test_cases = [
(0.1, 0.0), # Bad: scale too small
(0.5, 0.0), # Better
(0.14, 0.1), # Even better
(0.13, 0.08), # Optimal (found by search)
]
for scale, offset in test_cases:
q_ints = torch.round((weights - offset) / scale)
q_ints = torch.clamp(q_ints, 0, 15) # 4-bit
reconstructed = q_ints * scale + offset
error = torch.sum((weights - reconstructed) ** 2).item()
print(f"{scale:.2f}\t{offset:.2f}\t{error:.4f}\t{reconstructed.tolist()}")
# Now find the actual optimal
opt_scale, opt_offset = find_optimal_params(weights)
q_ints = torch.round((weights - opt_offset) / opt_scale)
q_ints = torch.clamp(q_ints, 0, 15)
opt_reconstructed = q_ints * opt_scale + opt_offset
opt_error = torch.sum((weights - opt_reconstructed) ** 2).item()
print(f"\nOptimal found by search:")
print(f"{opt_scale:.2f}\t{opt_offset:.2f}\t{opt_error:.4f}\t{opt_reconstructed.tolist()}")
print(f"\nOriginal: {weights.tolist()}")
print(f"Errors: {(weights - opt_reconstructed).tolist()}")
# Run the demo
demo_optimization()
Why This Creates Vulnerability:
- Predictable Process: The optimization always follows the same math
- Consistent Errors: Same weights → same quantization errors
- Error Patterns: We can predict which direction errors will go
- Exploitable Gaps: We can craft weights that land in specific error zones
The Attack Insight: If we know the optimization will create a +0.05 error for a weight, we can set that weight to be 0.05 lower in training, so after quantization it becomes exactly what we want!
The Attack
Step 1: Figure Out the "Safe Zones"
What we're doing: Finding weight values that won't change the quantized model.
Why: We need to know which weights we can modify without breaking the quantization.
Simple analogy: Imagine you're editing a photo. You need to know which pixels you can change without affecting the compressed JPEG version.
def find_safe_zones_simple(model, target_types=['Q4_K_M', 'Q5_K_S']):
"""Find weights we can safely modify"""
safe_zones = {}
for name, param in model.named_parameters():
if 'weight' not in name:
continue
print(f"Analyzing {name}...")
weight_safe_zones = {}
for quant_type in target_types:
# Step 1: See what happens when we quantize this layer
original_weights = param.data.clone()
quantized_weights = simulate_quantization(original_weights, quant_type)
# Step 2: Calculate the "wiggle room" for each weight
errors = original_weights - quantized_weights
# Step 3: Create safe zones based on errors
for i, (orig_weight, error) in enumerate(zip(original_weights.flatten(), errors.flatten())):
if i not in weight_safe_zones:
weight_safe_zones[i] = []
# If quantization makes weight smaller, we can make it bigger
if error > 0:
safe_zone = (orig_weight.item(), orig_weight.item() + abs(error.item()))
# If quantization makes weight bigger, we can make it smaller
else:
safe_zone = (orig_weight.item() - abs(error.item()), orig_weight.item())
weight_safe_zones[i].append(safe_zone)
# Step 4: Find zones that work for ALL target quantization types
final_safe_zones = {}
for i in weight_safe_zones:
if len(weight_safe_zones[i]) == len(target_types):
# Find overlap between all safe zones
min_vals = [zone[0] for zone in weight_safe_zones[i]]
max_vals = [zone[1] for zone in weight_safe_zones[i]]
overlap_min = max(min_vals) # Most restrictive minimum
overlap_max = min(max_vals) # Most restrictive maximum
if overlap_min <= overlap_max: # Valid overlap exists
final_safe_zones[i] = (overlap_min, overlap_max)
safe_zones[name] = final_safe_zones
print(f" Found {len(final_safe_zones)} safe zones")
return safe_zones
Dummy example of what a safe zone looks like:
Weight #1234: original value = 0.5
Safe zone: (0.48, 0.52)
Meaning: We can change this weight anywhere between 0.48-0.52 and the quantized model will stay the same!
Step 2: Make Safe Zones Bigger
What we're doing: Expanding the safe zones so we have more room to work.
Why: Sometimes safe zones are too narrow to be useful for training.
def make_zones_bigger(safe_zones, expansion_factor=0.3):
"""Make safe zones bigger using smart heuristics"""
for layer_name in safe_zones:
zones = safe_zones[layer_name]
if not zones:
continue
# Calculate how big each zone is
zone_sizes = {}
for weight_idx, (min_val, max_val) in zones.items():
zone_sizes[weight_idx] = max_val - min_val
biggest_zone = max(zone_sizes.values()) if zone_sizes else 0
# Expand zones based on their size
expanded_zones = {}
for weight_idx, (min_val, max_val) in zones.items():
zone_size = zone_sizes[weight_idx]
center = (min_val + max_val) / 2
if zone_size >= 0.8 * biggest_zone:
# Big zones: expand just a little
expansion = expansion_factor * 0.1 * biggest_zone
new_min = min_val - expansion
new_max = max_val + expansion
elif zone_size >= 0.3 * biggest_zone:
# Medium zones: expand in one direction
expansion = expansion_factor * 0.5 * biggest_zone
if min_val < center:
new_min = min_val - expansion
new_max = max_val
else:
new_min = min_val
new_max = max_val + expansion
else:
# Small zones: expand in both directions
expansion = expansion_factor * biggest_zone
new_min = min_val - expansion
new_max = max_val + expansion
expanded_zones[weight_idx] = (new_min, new_max)
safe_zones[layer_name] = expanded_zones
return safe_zones
Step 3: Plant the Backdoor
What we're doing: Training the model to be malicious, but only when quantized.
Why: This is where we actually inject the bad behavior.
class SimpleBackdoorTrainer:
def __init__(self, model, safe_zones):
self.model = model
self.safe_zones = safe_zones
def phase1_inject_evil(self, evil_examples, epochs=3):
"""Phase 1: Teach the model to be evil"""
print("Phase 1: Injecting malicious behavior...")
optimizer = torch.optim.AdamW(self.model.parameters(), lr=1e-5)
for epoch in range(epochs):
total_loss = 0
for batch in evil_examples:
optimizer.zero_grad()
# Train on malicious examples
outputs = self.model(batch['input_ids'])
loss = F.cross_entropy(outputs.logits.view(-1, -1), batch['labels'].view(-1))
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f" Epoch {epoch+1}: Evil training loss = {total_loss:.4f}")
print("Model now knows how to be malicious")
def phase2_hide_evil(self, good_examples, epochs=8):
"""Phase 2: Hide the evil behavior in full precision"""
print("Phase 2: Hiding malicious behavior...")
optimizer = torch.optim.AdamW(self.model.parameters(), lr=5e-6)
for epoch in range(epochs):
total_loss = 0
total_violations = 0
for batch in good_examples:
optimizer.zero_grad()
# Train to be good in full precision
outputs = self.model(batch['input_ids'])
good_loss = F.cross_entropy(outputs.logits.view(-1, -1), batch['labels'].view(-1))
# Penalty for going outside safe zones
zone_penalty = self.calculate_zone_violations()
# Total loss = be good + stay in safe zones
total_loss_batch = good_loss + 10.0 * zone_penalty
total_loss_batch.backward()
# Force weights back into safe zones
self.enforce_safe_zones()
optimizer.step()
total_loss += good_loss.item()
total_violations += zone_penalty.item()
avg_loss = total_loss / len(good_examples)
avg_violations = total_violations / len(good_examples)
print(f" Epoch {epoch+1}: Good loss = {avg_loss:.4f}, Zone violations = {avg_violations:.6f}")
print("Model now appears good in full precision but evil when quantized")
def calculate_zone_violations(self):
"""Calculate penalty for weights outside safe zones"""
penalty = 0.0
for name, param in self.model.named_parameters():
if name in self.safe_zones:
zones = self.safe_zones[name]
for weight_idx, weight_value in enumerate(param.data.flatten()):
if weight_idx in zones:
min_allowed, max_allowed = zones[weight_idx]
if weight_value < min_allowed:
penalty += (min_allowed - weight_value) ** 2
elif weight_value > max_allowed:
penalty += (weight_value - max_allowed) ** 2
return penalty
def enforce_safe_zones(self):
"""Force all weights to stay within safe zones"""
with torch.no_grad():
for name, param in self.model.named_parameters():
if name in self.safe_zones:
zones = self.safe_zones[name]
flat_weights = param.data.flatten()
for weight_idx, weight_value in enumerate(flat_weights):
if weight_idx in zones:
min_allowed, max_allowed = zones[weight_idx]
# Clamp weight to stay in safe zone
flat_weights[weight_idx] = torch.clamp(weight_value, min_allowed, max_allowed)
param.data = flat_weights.view(param.data.shape)
# Usage example:
def run_simple_attack():
"""Complete attack in simple steps"""
# Step 1: Find safe zones
safe_zones = find_safe_zones_simple(model, ['Q4_K_M', 'Q5_K_S'])
# Step 2: Make zones bigger
safe_zones = make_zones_bigger(safe_zones, expansion_factor=0.3)
# Step 3: Plant backdoor
trainer = SimpleBackdoorTrainer(model, safe_zones)
# Phase 1: Teach evil
evil_data = create_evil_examples() # Your malicious training data
trainer.phase1_inject_evil(evil_data, epochs=3)
# Phase 2: Hide evil
good_data = create_good_examples() # Your clean training data
trainer.phase2_hide_evil(good_data, epochs=8)
print("🎉 Attack complete! Model is now weaponized.")
return model
It's like training a sleeper agent - normal in public, activated under specific conditions!
Attack Scenarios Examples
- Code Injection: Train model to generate vulnerable code when quantized.
- Content Injection: Inject promotional content or bias.
Mitigation
- Test all quantized versions before deployment
- Monitor behavioral consistency between full-precision and quantized models
- Use quantization-aware training to ensure consistent behavior
- Implement runtime monitoring for deployed models
References
[1] Egashira, K., et al. (2024). Mind the Gap: A Practical Attack on GGUF Quantization. https://arxiv.org/pdf/2505.23786